Overfitting
Da Wikipedia, l'enciclopedia libera.
Vai a:
Navigazione,
cerca
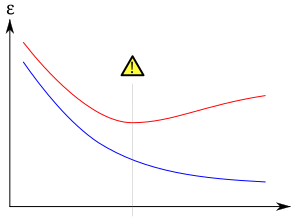

Overfitting. La curva blu mostra l'andamento dell'errore nel classificare i dati di
training, mentre la curva rossa mostra l'errore nel classificare i dati di
test o
validazione. Se l'errore di validazione aumenta mentre l'errore aui dati di training diminuisce, ciò indica che siamo in presenza di un possibile caso di overfitting.
In
statistica, si parla di
overfitting (
eccessivo adattamento) quando un modello statistico si adatta ai dati osservati (il
campione) usando un numero eccessivo di parametri. Un modello assurdo e sbagliato può adattarsi perfettamente se è abbastanza complesso rispetto alla quantità di dati disponibili. Spesso si sostiene che l'overfitting è una violazione della legge del
Rasoio di Occam.
Il concetto di overfitting è molto importante anche nell'
apprendimento automatico e nel
data mining. Di solito un
algoritmo di apprendimento viene
allenato usando un certo insieme di esempi (il
training set appunto), ad esempio situazioni tipo di cui è già noto il risultato che interessa prevedere (
output). Si assume che l'algoritmo di apprendimento (il
learner) raggiungerà uno stato in cui sarà in grado di predire gli output per tutti gli altri esempi che ancora non ha visionato, cioè si assume che il modello di apprendimento sarà in grado di
generalizzare. Tuttavia, soprattutto nei casi in cui l'apprendimento è stato effettuato troppo a lungo o dove c'era uno scarso numero di esempi di allenamento, il modello potrebbe adattarsi a caratteristiche che sono specifiche solo del training set, ma che non hanno riscontro nel resto dei casi; perciò, in presenza di overfitting, le prestazioni (cioè la capacità di adattarsi/prevedere) sui dati di allenamento aumenteranno, mentre le prestazioni sui dati non visionati saranno peggiori.
Sia nella statistica che nel machine learning, per evitare l'overfitting, è necessario attuare particolari tecniche, come la
cross-validation e l'
arresto anticipato, che indichino quando un ulteriore allenamento non porterebbe ad una migliore generalizzazione. Nel
treatment learning si evita l'overfitting utilizzando il valore di supporto migliore e minimale.

") Ho messo la drawline sulla candela dell'ipotetico minimo. Vediamo se lo prendo.
Ho messo la drawline sulla candela dell'ipotetico minimo. Vediamo se lo prendo.



