Stai usando un browser molto obsoleto. Puoi incorrere in problemi di visualizzazione di questo e altri siti oltre che in problemi di sicurezza. .
Dovresti aggiornarlo oppure usarne uno alternativo, moderno e sicuro.
Dovresti aggiornarlo oppure usarne uno alternativo, moderno e sicuro.
Overfitting
- Creatore Discussione GiuliaP
- Data di Inizio
Imar
Forumer attivo
Quindi voglio dire, quanto peso dai alla possibilità che il periodo esaminato per la vendita della volatilità fosse il "periodo migliore di sempre per quel trade"?
Ah, non ne ho proprio idea (e se qualcuno ti dice di poter rispondere a questa domanda… magari usando solo la logica teorica ...............diffida tanto tanto tanto).
Il trading – per quanto mi riguarda – è al 100% incertezza (salvo particolari casi di “vantaggio tecnologico”, per così dire…. concetto mobile nel tempo, a Waterloo il vantaggio tecnologico erano i piccioni viaggiatori….)
Per i dati storici sulla correlazione, ricordo che esiste un apposito indice sul sito del CBOE.
Rigirado ai tuoi (Luciom) commenti sulla EHM, direi che quanto segue
Dubitare della possibilità teorica che il singolo investitore riesca a battere il mercato però è ben diverso dal dire che quel singolo investitore sono io nella pratica (è qui che ci vuole il leap of faith imho)
riassume ottimamente anche il mio pensiero.
Tranquillo, è finita: li ho stesi tutti!!!

 .... piuttosto diciamo presi per sfinimento .....
.... piuttosto diciamo presi per sfinimento ..... In primo luogo, i nostri differenti approcci al rischio derivano sicuramente dalle necessità personali conseguenti gli strumenti che siamo abituati ad utilizzare.
Magari è solo semantica, se vuoi puoi anche definirle “differenti necessità personali”, ma se si vuole essere più chiari, io credo che i nostri differenti approcci al rischio derivano da differenti FUNZIONI DI UTILITA’ che noi associamo (consciamente od inconsciamente) al trading e che non sono state esplicitate PRIMA di iniziare la discussione.
Il covered call è meno rischioso del long spot, se la funzione di utilità prevede di massimizzare lo Sharpe ratio, e la cosa non è discutibile, dato che l’unico dato razionale che abbiamo per deciderlo sono… i dati degli ultimi 30 anni (il futuro sarà di sicuro diverso, ma dato che nessuno di noi lo conosce, l’unica cosa che possiamo fare è basarci prudentemente sulla historia magistra vitae…)
Al contrario, se la funzione di utilità prevede la massimizzazione del rendimento capitale investito, penso anch’io che il covered call sia meno efficiente del long spot.
PER ME, “meno efficiente” non è sinonimo di “più rischioso”, ma a quanto pare per PGP si… ed alla fine l’importante è capirsi (maledetta semantica
")
 ) e non innalzare al rango di concetti universali ragionamenti forzatamente soggettivi (per me sta qui il limite – non piccolo - dell'attegggiamento, più che dei ragionamenti, di PGP).
) e non innalzare al rango di concetti universali ragionamenti forzatamente soggettivi (per me sta qui il limite – non piccolo - dell'attegggiamento, più che dei ragionamenti, di PGP).In terzo luogo, considerare il rischio come uno scalare ti limita immensamente, costringendoti ad approssimazioni pericolose e rischiando addirittura di diventare fuorviante. Perché anche stringendo le ipotesi al massimo e definendo alla perfezione la tua strategia (ma sarebbe meglio parlare di "piano operativo"), potrai sempre e comunque avere problemi imprevisti che ti costringeranno a ricalcolare il tutto. Salvo aver già una corretta e preziosissima visione d'insieme considerando il rischio in maniera più complessa, ovvero come una funzione sia dello spazio che del tempo (perdona la deformazione professionale di chiamare "spazio" la dimensione della grandezza a rischio).
Perfetto, perfettissimo in teoria (come tutto il post "riassuntivo"), ma in pratica, tutto i ragionamenti sul rischio servono SE e SOLO SE arrivi a determinare una allocazione di capitale che reputi necessaria ad una data strategia.
Puoi fare tutti i voli pindarici che vuoi, andare e venire dalla settima dimensione…… ma alla fine – che ti piaccia o no – questa allocazione di capitale in cui esprimi la tua visione di rischio è uno scalare…. (al momento della decisione, vale il "hic et nunc": il tuo spazio è qui, il tuo tempo è adesso... tutto il resto è fuffa) che magari scopriresti – more often than not – essere funzione diretta di concetti quali “massima perdita” o “margini” di cui tu non vuoi (giustamente, in teoria, ma la pratica è sempre un po’ diversa…) sentir parlare.
Del resto i cimiteri sono stracolmi di opzionisti e "megagestori" più o meno illustri ….
Ovvio, ma questo non dimostra nulla, soprattutto non vuol dire che non capissero i rischi, magari hanno accettato scientemente di correrli………………
Ti lascerò a bocca aperta: io il rischio lo sommo, in ipotesi assumibili, anche con sottostanti differenti e strategie orizzontali
Ah, ma io ti lascio ancora più a bocca aperta (e senza neanche un colloquio privato col kamikaze Kurt.... incredibile, vero??
 ): quanto scrivi è solo una ovvia conseguenza di quanto hai esposto finora…. (tra l’altro, MOLTO MOLTO più condivisibile
): quanto scrivi è solo una ovvia conseguenza di quanto hai esposto finora…. (tra l’altro, MOLTO MOLTO più condivisibile  dell’affermazione che “il covered call è più rischioso del long spot” ….)
dell’affermazione che “il covered call è più rischioso del long spot” ….)Infatti, se la diminuzione del rischio complessivo di portafoglio è connessa alla presenza di correlazioni …. e le correlazioni vengono assunte instabili (come sono, soprattutto nei momenti di stress finanziario, in cui tutto si correla più o meno ad 1) è chiaro che il tuo ragionamento non cambia - anzi si rafforza - anche assumendo sottostanti diversi.
C’è un bell esempio di questo concetto in “Hedge fund market wizard”, nell’intervista a Jamie Mai (p. 237) viene illustrato un trade su una “worst of an option” in cui l’obiettivo è proprio sfruttare una stima di correlazione inversa tra AUD e CHF rispetto all'Euro che il MM fa in base a parametri storici, di lì a poco destinati a saltare….

Ma io ancora non capisco di cosa stiamo parlando...
Il payoff lo conosco (lo posso perfino complicare a piacere attraverso le strategie...), la pdf in quel preciso istante me la dà il mercato.
Payoff * pdf (integrato e scontato) = fair price (stimato dal mercato ed in quel preciso momento).
Ho una pdf diversa? Fine, prendo posizione.
Qualcuno ha una pdf diversa e io riesco a hedgiarmi con la pdf di mercato? Fine, gli faccio da controparte.
Etc...
Come tengo a bada i miei rischi? What-if, ad esempio... Magari poi decido di hedgiare i fattori che mi danno più fastidio...
Quindi?
Ma io non sto parlando di modelli, quanto vale la call x me lo dice la put x, la call x+d, la call x-d, e cosí via. A me sembra che il mercato sia model-free. Tutto è poi filtrato da B&S, ma non potrebbe essere altrimenti...
Ecco, leggere Skew è quasi sempre come una boccata d'aria fresca quando esci dal fumo....... come riportare i piedi per terra dopo essere stati nello spazio .............. lo spazio è bello, ma vuoi mettere la soddisfazione di toccare di nuovo terra dopo tanti viaggi teorici .... nella 7° dimensione
.
Ultima modifica:
GiveMeLeverage
& I will remove the world
Parlando di massimizzazione dell'entropia, gradi di libertà, programmazione e algoritmi mi è venuto in mente un gioco al quale provare ad applicare questi concetti (non l'AI che è al di sopra delle possibilità & ambizioni )
Si tratta di una variante del mastermind, per la quale anni fa avevo realizzato un mini-programma in vb (+ basic che visual).
Immagino conosciate tutti il mastermind: si tratta di indovinare una seguenza di lunghezza n composta da m simboli (numeri, colori, lettere, ecc) sulla base di una serie di indizi, qui una descrizione più completa se servisse:
Mastermind (board game) - Wikipedia, the free encyclopedia
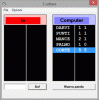
Nella "mia" variante la lunghezza è di 5 e i simboli sono le 26 lettere dell'alfabeto (non ripetute), inoltre la sequenza o codice deve avere un senso compiuto nella lingua italiana.. detto più semplicemente si tratta di indovinare una parola i 5 lettere tutte diverse.
L'immagine in allegato penso esemplifichi bene il funzionamento, allego anche l'eseguibile se qlc si volesse dilettare.
)Si tratta di una variante del mastermind, per la quale anni fa avevo realizzato un mini-programma in vb (+ basic che visual).
Immagino conosciate tutti il mastermind: si tratta di indovinare una seguenza di lunghezza n composta da m simboli (numeri, colori, lettere, ecc) sulla base di una serie di indizi, qui una descrizione più completa se servisse:
Mastermind (board game) - Wikipedia, the free encyclopedia
Nella "mia" variante la lunghezza è di 5 e i simboli sono le 26 lettere dell'alfabeto (non ripetute), inoltre la sequenza o codice deve avere un senso compiuto nella lingua italiana.. detto più semplicemente si tratta di indovinare una parola i 5 lettere tutte diverse.
L'immagine in allegato penso esemplifichi bene il funzionamento, allego anche l'eseguibile se qlc si volesse dilettare.
Allegati
GiveMeLeverage
& I will remove the world
Il programma (che risale al lontano 2003) è tutt'altro che ottimizzato:
1) come primo tentativo di indovinare la parola-codice, il computer prende una parola a random dal vocabolario;
2) nei tentativi successivi pesca (sempre a random) da un sottoinsieme via via più stretto del vocabolario che contiene soltanto le possibili soluzioni.
E' evidente che per rendere l'algoritmo di ricerca del codice più efficiente, sarebbe necessario scegliere le domande un po' più intelligentemente che a caso.
Una delle possibilità più promettenti mi pare sia quella di minimizzare la cardinalità dell'insieme delle soluzioni possibili.
Se una domanda mi riduce l'insieme da 1000 a 500 elementi e un'altra da 1000 a 300 elementi, mi pare logico (benché difficile da dimostrare) che la seconda sia preferibile per arrivare quanto più velocemente possibile alla soluzione.
1) come primo tentativo di indovinare la parola-codice, il computer prende una parola a random dal vocabolario;
2) nei tentativi successivi pesca (sempre a random) da un sottoinsieme via via più stretto del vocabolario che contiene soltanto le possibili soluzioni.
E' evidente che per rendere l'algoritmo di ricerca del codice più efficiente, sarebbe necessario scegliere le domande un po' più intelligentemente che a caso.
Una delle possibilità più promettenti mi pare sia quella di minimizzare la cardinalità dell'insieme delle soluzioni possibili.
Se una domanda mi riduce l'insieme da 1000 a 500 elementi e un'altra da 1000 a 300 elementi, mi pare logico (benché difficile da dimostrare) che la seconda sia preferibile per arrivare quanto più velocemente possibile alla soluzione.
GiveMeLeverage
& I will remove the world
Potrei quindi costruire per ciascuna risposta ad una data domanda i relativi insiemi delle soluzioni possibili.
Le risposte sono (al massimo) 19:
0,0 -> insieme 1
0,1 -> insieme 2
..
0,5 -> insieme 6
1,1 -> insieme 7
..
1,5 -> insieme 11
..
3,5 -> insieme 18
4,4 -> insieme 19
Quindi avrò non un solo numero da minimizzare, bensì 19 numeri -- un po' come minimizzare il rischio di Giulia, che non è uno scalare bensì una funzione o un vettore, vedete che non sono (totalmente) off topic
Qui potrebbe venir comodo il concetto di massima entropia (l'entropia aumenta tanto più i numeri sono distribuiti uniformemente tra i vari insiemi, ma se sono distribuiti uniformemente ciascun insieme conterrà mediamente meno elementi, ecc.).
Visto che però l'entropia mi sta antipatica perché mi ha fatto fare la figura del pirla, lascio ad altri tentare questa strada.
Le risposte sono (al massimo) 19:
0,0 -> insieme 1
0,1 -> insieme 2
..
0,5 -> insieme 6
1,1 -> insieme 7
..
1,5 -> insieme 11
..
3,5 -> insieme 18
4,4 -> insieme 19
Quindi avrò non un solo numero da minimizzare, bensì 19 numeri -- un po' come minimizzare il rischio di Giulia, che non è uno scalare bensì una funzione o un vettore, vedete che non sono (totalmente) off topic
Qui potrebbe venir comodo il concetto di massima entropia (l'entropia aumenta tanto più i numeri sono distribuiti uniformemente tra i vari insiemi, ma se sono distribuiti uniformemente ciascun insieme conterrà mediamente meno elementi, ecc.).
Visto che però l'entropia mi sta antipatica perché mi ha fatto fare la figura del pirla, lascio ad altri tentare questa strada.
GiveMeLeverage
& I will remove the world
(ditemi se il mio monologo è pure gibberish o può rivestire qlc interesse, intanto continuo)
Altra strada: calcolare il valore atteso e minimizzare quello
valore atteso = Sommatoria (quantità * probabilità)
dove la quantità è la cardinalità dei 19 insiemi e la probabilità è quella di ricevere una data risposta invece di un'altra alla mia domanda;
quantità = N elementi dell'i-esimo insieme
probabilità = N elementi dell'i-esimo insieme / N elementi totali
(0,1 è solitamente molto più probabile di 5,5 perché l'insieme 0,1 contiene molti più elementi dell'insieme 5,5 che ne contiene 1 solo e cioè la parola cercata)
Ma se due domande avessero pari valore atteso, quale scegliere?
Oltre al valore atteso potremmo introdurre anche il rischio, ma come lo definiamo?
Altra strada: calcolare il valore atteso e minimizzare quello
valore atteso = Sommatoria (quantità * probabilità)
dove la quantità è la cardinalità dei 19 insiemi e la probabilità è quella di ricevere una data risposta invece di un'altra alla mia domanda;
quantità = N elementi dell'i-esimo insieme
probabilità = N elementi dell'i-esimo insieme / N elementi totali
(0,1 è solitamente molto più probabile di 5,5 perché l'insieme 0,1 contiene molti più elementi dell'insieme 5,5 che ne contiene 1 solo e cioè la parola cercata)
Ma se due domande avessero pari valore atteso, quale scegliere?
Oltre al valore atteso potremmo introdurre anche il rischio, ma come lo definiamo?
GiveMeLeverage
& I will remove the world
In un approccio minmax, il rischio da minimizzare sarebbe:
max (N elementi dell'i-esimo insieme) per i che va da 1 a 19
Assomiglierebbe molto al MDD (quindi suppongo piacerà poco a Giulia).
In alternativa potremmo usare una misura più simile alla volatilità, p.e. la varianza attorno al valore atteso, e minimizzare quella.
Però come ben dice Imar, le misure di rischio (o di rendimento pesato sul rischio come Sharpe & simili) hanno poco significato se non nel contesto di una nostra funzione di utilità.
In questo giochetto, qual è la funzione d'utilità che vogliamo ottimizzare?
Sembrerebbe il numero di domande per giungere alla soluzione, esplicitamente dichiarata qualche messaggio fa.
Però implicitamente cerchiamo anche un algoritmo semplice e veloce: se questi non fossero dei vincoli, allora la cosa più efficiente sarebbe un approccio brute force dove si esplora ogni singolo ramo dell'albero delle possibili risposte (ma si rischia di diventare vecchi tra le fronde: 1381 parole * 19 risposte = ca. 26.000 rami ad ogni passaggio, dopo 5 passaggi siamo a 1,2 * 10^22 rami, supponendo di esplorare un miliardo di rami al secondo ci metteremmo poco meno di 400.000 anni).
Limitiamoci dunque agli algoritmi semplici & veloci, però anche qui dire "numero minimo di domande" è meno univoco di quanto sembri, perché naturalmente non avremmo un numero fisso di domande per giungere alla soluzione, bensì un numero medio attorno al quale ci sarà una distribuzione.
Quale minimo vogliamo? Il minimo delle medie, il minimo nel worst case, il minimo nel best case (in tal caso dovremmo scegliere le domande solo dal pool delle possibili soluzioni) ecc. ?
Per poter scegliere più agevolmente la propria funzione d'utilità, potremmo introdurre un nuovo elemento nel gioco, la remunerazione.
P.e.: al code-breaker ad inizio gioco viene riconosciuta una somma di 5 euro e ciascuna domanda gli costa 1 euro.
max (N elementi dell'i-esimo insieme) per i che va da 1 a 19
Assomiglierebbe molto al MDD (quindi suppongo piacerà poco a Giulia).
In alternativa potremmo usare una misura più simile alla volatilità, p.e. la varianza attorno al valore atteso, e minimizzare quella.
Però come ben dice Imar, le misure di rischio (o di rendimento pesato sul rischio come Sharpe & simili) hanno poco significato se non nel contesto di una nostra funzione di utilità.
In questo giochetto, qual è la funzione d'utilità che vogliamo ottimizzare?
Sembrerebbe il numero di domande per giungere alla soluzione, esplicitamente dichiarata qualche messaggio fa.
Però implicitamente cerchiamo anche un algoritmo semplice e veloce: se questi non fossero dei vincoli, allora la cosa più efficiente sarebbe un approccio brute force dove si esplora ogni singolo ramo dell'albero delle possibili risposte (ma si rischia di diventare vecchi tra le fronde: 1381 parole * 19 risposte = ca. 26.000 rami ad ogni passaggio, dopo 5 passaggi siamo a 1,2 * 10^22 rami, supponendo di esplorare un miliardo di rami al secondo ci metteremmo poco meno di 400.000 anni).
Limitiamoci dunque agli algoritmi semplici & veloci, però anche qui dire "numero minimo di domande" è meno univoco di quanto sembri, perché naturalmente non avremmo un numero fisso di domande per giungere alla soluzione, bensì un numero medio attorno al quale ci sarà una distribuzione.
Quale minimo vogliamo? Il minimo delle medie, il minimo nel worst case, il minimo nel best case (in tal caso dovremmo scegliere le domande solo dal pool delle possibili soluzioni) ecc. ?
Per poter scegliere più agevolmente la propria funzione d'utilità, potremmo introdurre un nuovo elemento nel gioco, la remunerazione.
P.e.: al code-breaker ad inizio gioco viene riconosciuta una somma di 5 euro e ciascuna domanda gli costa 1 euro.
Ultima modifica:
GiveMeLeverage
& I will remove the world
Fermo restando che puoi postare quanto, quando, e cosa vuoi (in "overfitting" non si va mai ot), qual è lo scopo finale del monologo?
")
Rivisitare i soliti temi sotto una luce diversa.
In particolare mi sarebbe piaciuto capire se diverse concezioni del rischio portano a differenti strategie, e confrontare queste startegie in un caso concreto.
Cambiare ambito per un momento (rispetto agli investimenti finanziari) potrebbe avere l'effetto di affrontare a mente più libera le conseguenze delle nostre convinzioni.
Però il presupposto è che il nuovo ambito intrighi, altrimenti il monologo resta tale.
GiuliaP
The Dark Side
Rivisitare i soliti temi sotto una luce diversa.
In particolare mi sarebbe piaciuto capire se diverse concezioni del rischio portano a differenti strategie, e confrontare queste startegie in un caso concreto...
L'idea è interessante, ma va fatta una premessa: è molto (troppo) ambizioso scegliere la strategia anche in funzione del rischio. La strategia la sceglie il tuo modello in base alle (ben poche) opportunità che offre il mercato. Io credo che voler selezionare tali opportunità anche in funzione del rischio è chiedere molto (troppo).
Un esempio facile: non è che scegli long piuttosto che covered call perché rischi meno: scegli in funzione della tua "previsione", ovvero del tuo modello, ovvero del mercato. In seconda battuta la valutazione del rischio, se la fai bene, ti aiuta a costruire un adeguato money management.
Ovvero a parità di ogni altro fattore, se il tuo modello ti consiglia "covered call", il tuo risk management ti indicherà comunque di allocare meno risorse rispetto al long (e dire il contrario, "secondo me", è sbagliato senza se e senza ma: non esiste una "diversa concezione del rischio" che possa invertire la cosa).
Fin troppe volte, in tanti anni, ho assistito a selezioni/modifiche di strategie in funzione del rischio (o dei margini), addirittura sbagliando completamente anche nella valutazione dello stesso (errore nell'errore), senza capire minimamente che così facendo veniva stravolta completamente la previsione, e la strategia, che evidentemente non esisteva neanche.
Cambiare ambito per un momento (rispetto agli investimenti finanziari) potrebbe avere l'effetto di affrontare a mente più libera le conseguenze delle nostre convinzioni.
Però il presupposto è che il nuovo ambito intrighi, altrimenti il monologo resta tale.
Ti confesso che l'esempio da te scelto non mi ha "preso": lo vedo fuorviante e troppo distante dall'obiettivo

Mi sembra più un problema di ricerca operativa, che di gestione del rischio.
Ultima modifica:
GiveMeLeverage
& I will remove the world
Allora seppelliamolo.Ti confesso che l'esempio da te scelto non mi ha "preso": lo vedo fuorviante e troppo distante dall'obiettivo
Mi sembra più un problema di ricerca operativa, che di gestione del rischio.

(L'ho incontrato per caso andando dietro all'entropia, ovviamente ero prevenuto avendolo programmato in passato; per inciso, qui secondo me spiega bene la differenza pratica tra massimizzare l'entropia e massimizzare i gradi di libertà: http://www.philos.rug.nl/~barteld/master.pdf )
Ultima modifica:
Similar threads
- Risposte
- 0
- Visite
- 98
- Risposte
- 0
- Visite
- 40
Users who are viewing this thread
Total: 1 (members: 0, guests: 1)